 גיא קורלנד | צילום: יח"צ
גיא קורלנד | צילום: יח"צ
האם המפץ הגדול לפני הקריסה הגדולה? או לאן הולך עולם מסדי הנתונים?
כמעט 50 שנה שלטו בעולם ענקי טכנולוגיה אשר חילקו את העולם ביניהם. משנות ה-60 של המאה הקודמת ועד סוף העשור הראשון של שנות ה-2000, עולם מסדי הנתונים נשלט כמעט בבלעדיות ע"י "ענקים" כמו Oracle, IBM, Microsoft. אמנם הייתה סוג של תחרות בין הענקים ואפילו היה "גמד" שובב (MySQL) שניסה לאתגר את המודל העסקי, אבל כולם הביאו לשוק את אותו פתרון מוכר למידול המידע טבלאי (Relational), ואותו קיבעון מחשבתי שדרש לא לסטות מהסטנדרט המוכר לשאילתות (SQL).
הפתרון הנפוץ דרש מהמפתחים להתאמץ ולהתאים את הבעיה שברצונם לפתור (התוכנה המפותחת) למודל היחיד האחיד והסטנדרטי ש'הענקים' אפשרו. בנוסף, הוא אף כפה עליהם להכיר בכך שלא יוכלו לגדול בקצב מהיר מידי וכי קיימת הגבלה מובנת ביכולת עיבוד המידע, אשר תגביל את היכולת העסקית של הארגון לאפשר גדילה מהירה. מודל זה יצר תסכול רב בקרב המפתחים, עד כדי כך שברוב ארגוני הפיתוח מונה מומחה (DBA) אשר כל תפקידו היה לתמוך ולעזור בעזרת קסמים וטריקים למיניהם, לסחוט עוד קצת את הלימון בכדי לאפשר למפתחים להגיע הכי קרוב שאפשרי ליעדם.
כבר בסוף שנות ה-90 היה ברור שהמודל הנוכחי לא מספק. עם פריחת האינטרנט, מסדי הנתונים החלו להוות חסם ברור לגדילה המהירה ולצורך לספק חווית משתמש מהירה וחלקה. משתמשי הקצה כבר היו פחות סלחנים - אלו כבר לא היו ברובם עובדי מדינה שבויים אשר המתנה של 30 שניות לעדכון המסך נראתה להם כגזירת גורל הגיונית וזמן ללגום מכוס התה - אלא משתמשי קצה אשר סף סבלנותם נמדד בשניות בודדות.
וכך בסוף שנות ה-90 בואכה המילניום החדש החלו להופיע "רעידות" וכל מיני "גמדים" החלו לאתגר את המודל של הענקים. בתחילה עדיין רווחה האמונה כי לא ניתן להחליף את המודל וכל שניתן זה להוסיף שכבה נוספת, אשר במקרים מסוימים תאיץ את המודל הקיים אולם לא תחליף אותו (Cache). חברות רבות קמו על מנת לספק פתרון אשר יאיץ את מסדי הנתונים הקיימים ועד סוף העשור הראשון רבות מהן כבר נקנו ע"י הענקים (Gemfire, Coherence, TimesTen, Terracotta) או כמעט ונעלמו (משבר 2008 גם תרם את חלקו).
אולם זו רק הייתה דחיית הקץ, המפץ הגדול או בשמו היותר מוכר NoSQL (Not Only SQL) החל כבר בסוף העשור הראשון של המאה הזאת, כאשר העשור השני הביא איתו מאות חברות חדשות שאתגרו את המודל הישן והביאו לשוק אינספור מודלים חדשים. כל החידוש היה לבנות מודל המותאם לבעיה שהמפתחים מנסים לפתור ותוך כדי כך לוודא שהמודל תפור למידותיהם.
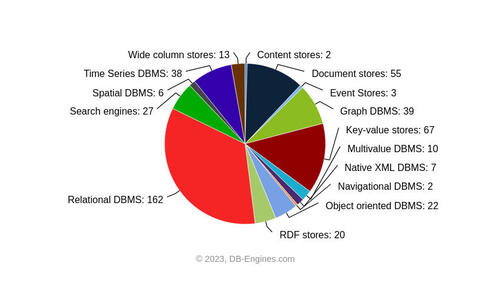
בצירוף מקרים מושלם המפץ הגדול קרה בחפיפה לעליית פופולריות הקוד הפתוח ורבים מהמוצרים החדשים החלו לצבור תמיכה ישירה בקרב המפתחים. במקרים רבים כבר לא היה צורך למנות מומחה (DBA) וכל מי שרצה יכל פשוט לבחור בחינם את המודל המתאים לצרכיו, לפשפש בקוד המוצר אם לא פעל עפ"י המצופה ואולי אף לתרום לשיפורו. צירוף המקרים לא הסתיים כאן. עם הופעת מחשוב הענן ובחפיפה כמעט מושלמת נסדק מודל נוסף. בתוך זמן קצר מפתחים רבים הבינו שלא רק שאינם צריכים עוד להתאים את המוצר למודל הישן, הם גם אינם צריכים עוד להתאמץ ולהכיר כיצד לנהל את המוצר בסביבת הייצור. למעשה, בלחיצת כפתור הם יכולים לבחור כמעט כל מוצר לפי צרכיהם, כמעט בלי צורך להכיר כיצד מנהלים את המוצר.
העשור השני של המאה הזאת התאפיין בפריחה מדהימה של מסדי נתונים מסוגים שונים, ושל כלים ואפשרויות חדשות. לפתע הכוח עבר למפתחים, כל מפתח יכול בלחיצת כפתור לבחור אחד ממאות מסדי הנתונים השונים הנגישים בענן, לשלב ביניהם ולבנות פתרון. ניתן לבצע את הפעולות כמעט ללא צורך במחשבה יתרה, למעט המחשבה הממוקדת בפתרון העסקי אותו המפתח רוצה להשיג. כל זאת התיישב יפה עם מתודולוגיה אשר רווחת בעשורים האחרונים כי כדאי ויש לפרק למיקרו שירותים זעירים (microservices) תוכנות מסובכות ורבות שלבים, כך שכל שירות מתמחה בחלק מוגדר של הבעיה הגדולה, תוך שהוא ניתן לניהול, עדכון ופיתוח באופן עצמאי. וכך החלו להופיע ארכיטקטורות מומלצות הכוללות מספר רב של מסדי נתונים שונים, לעיתים אפילו מעל תריסר.
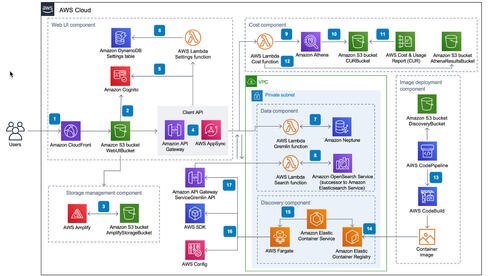
https://aws.amazon.com/solutions/implementations/aws-perspective/
אולם, אחרי שנים של התבדרות נראה כי בשנים האחרונות מחלחלת ההבנה כי התהליך לא יכול להימשך כך לעד, והחל תהליך של קריסה והתכנסות. לתהליך זה תורמים מספר גורמים: בראש ובראשונה, ככל שהארכיטקטורות גדלו והסתבכו כך גדלו העלויות בצורה דרמטית. בסופו של דבר, מספר רב של מסדי נתונים שונים דורש שכפול המידע ביניהם ותהליכי סנכרון אשר יבטיחו תמונה אחידה. מעבר לכך, ככל שהפתרונות כוללים מספר רב יותר של שלבים כך גובר הסיכון כי יפגעו הביצועים, כמו גם חווית משתמשי הקצה. כל זאת הביא לכך שבשנים האחרונות מתרחש תהליך של הרחבת מסדי הנתונים לתמיכה בריבוי מודלים, מה שמייצר פשרה מתבקשת: מצד אחד אין חזרה למודל טבלאי אחד ויחיד, ומצד שני, לא נדרש לחבר מספר רב של מסדי נתונים שונים לפתרון אחד.
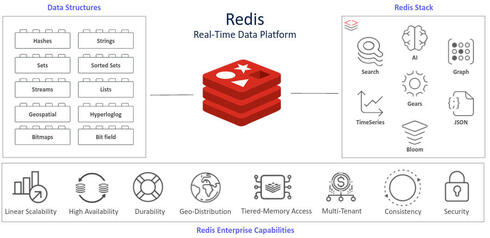
מסד נתונים אחד נדרש היום לספק מספר מודלים שונים באותו מוצר, כך שהמפתח מקבל חווית פיתוח אחידה ופשוטה ואין צורך בשכפול ובסנכרון מידע בין מסדי נתונים שונים. הדבר מוזיל את העלויות בצורה משמעותית, במקרים רבים משפר את ביצועי המערכת, ומעל לכל, משפר את חווית משתמשי הקצה.
לסיכום, נראה כי עולם מסדי הנתונים אשר עד לפני שני עשורים נתפס כעולם שמרני, איטי וחסר ברק, עומד שוב על סף מהפכה אשר באה כתיקון מתבקש למהפכה הקודמת שניפצה את המודל הישן לרסיסים. אנחנו ב'רדיס' מאמינים כי הקריסה הגדולה החלה לתוך מסדי נתונים אחודים. מסדי הנתונים המודרניים נדרשים לספק במוצר אחד פתרון לקשת רחבה של בעיות. במקביל, הם נדרשים לספק לכל בעיה את הפתרון האופטימלי אשר יאפשר מידול יעיל של המידע וגישה מהירה (low latency) למידע מכל מקום על הגלובוס, באופן המותאם לדרישות השוק הקיימות כיום, תוך שמירה על זמינות ואמינות גבוהה, אפילו במקרי קצה של קריסת תשתיות מחשוב באזורים גיאוגרפיים שלמים – אשר למרבה הפלא הדבר אינו נדיר כפי שהיה ניתן לחשוב.
גיא קורלנד הוא CTO of Incubations בחברת Redis
d&b – לדעת להחליט